编者按:2020 年 8 月 7 日,全球人工智能和机器人峰会(CCF-GAIR 2020)正式开幕。CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,香港中文大学(深圳)、雷锋网联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办。从 2016 年的学产结合,2017 年的产业落地,2018 年的垂直细分,2019 年的人工智能 40 周年,峰会一直致力于打造国内人工智能和机器人领域规模最大、规格最高、跨界最广的学术、工业和投资平台。
在GAIR大会的第二天,AI源创专场现场迎来了Zilliz合伙人兼技术布道者顾钧。顾钧同时代表Zilliz担任Linux AI基金会技术咨询委员会的投票成员,此前他历任华为IT战略专家,摩根士丹利副总裁等职务,现在致力于完善Milvus开源项目并推动该项目的商业化。

顾钧在GAIR2020的AI源创专场的演讲
顾钧的演讲主题为《Milvus:构建非结构性的数据服务》,他在演讲中着重介绍了Milvus开源项目的工作状况。他认为,数据分成结构化的数据,半结构化的数据,和非结构化数据。非结构化数据的总量非常巨大,但是如果想要从中挖掘更多的业务和价值,是非常困难的。
如何从非结构化数据中挖掘价值,顾钧提供了一些思路:首先会经过模型推理,模型推理这层主要负责的工作是把模型做出高效的、实时的Service,通过特征学习的方式,把非结构化数据转化成特征向量,这些可以在数据这层为这些所有的特征向量做集中的数据服务。
他还举了一些例子以印证其对于Milvus数据处理的思考。顾钧表示,AI的转型始之于算法,继之于服务。比如企查查有5500万张的中国企业商标的图片,如何用图片为自己的用户提供更好的服务。怎么样去让用户可以搜这些商标图片?通过Milvus,企查查把模型放在端侧进行部署,既可以在技术上减少障碍,又可以降低实际部署的成本。
以下为顾钧的现场演讲内容,雷锋网(公众号:雷锋网)作了不改变原意的编辑及整理:
大家下午好!非常荣幸参加这次全球人工智能与机器人峰会,非常高兴能在这里和大家一起分享我们的开源项目Milvus,我们希望帮大家在AI的场景下,以Milvus构建非结构性的数据服务。
我们的Milvus项目是为AI场景下提供数据服务的功能。我认为我们现在正处于一个从数字化转型向AI转型过渡的时期,并且我们处于AI转型的过程中非常关键的临界点。我们已经有了大量的可用的模型和算法,这些模型和算法都是开源的模型算法,模型很容易用起来形成初始的原型,而要把原型真正部署到生产的时候会面临怎么样处理好海量数据的问题,Milvus是针对AI场景下如何服务海量数据,解决这个问题的开源项目。
简单介绍一下研发技术软件的团队,我们的团队叫做Zilliz,是大数据相关的创业公司,以开源项目的模式在推进我们的开发工作。我们认为对基础软件来说开源是目前来说最重要的商业模式中的第一步。Milvus项目是LF AI项目组的项目,希望大家参与到这个项目中,无论是使用还是开发。目前Zilliz这个公司的角色是LinuxAI基金会项目的主要贡献者。
首先跟大家分享一下非结构数据服务究竟是什么意思。大家了解数据类的服务、云计算的话,中间有RDS的概念。RDS主要是针对关系型的数据提供数据服务,我们主要是针对非结构化数据提供的数据服务,我们称自己为UDS。

什么是非结构化数据?
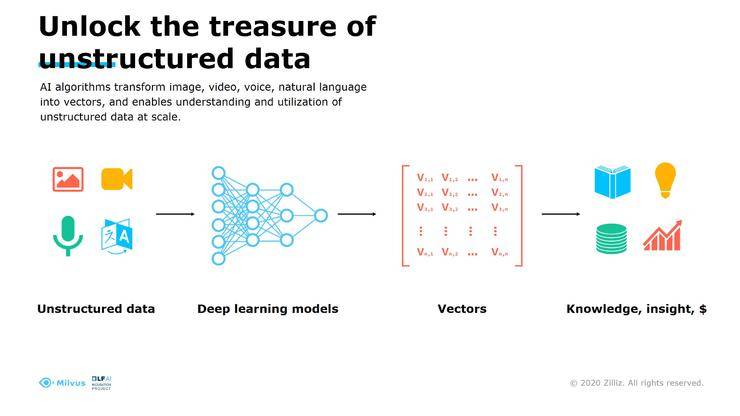
通常来讲,我们会把数据分成:结构化的数据,主要是金融领域中常见的数值、字符串。我们有大量的结构化数据库,就是为了解决结构化数据的挑战,包括大数据的技术,解决海量结构化数据的挑战。二是半结构化的数据,有一定格式的文本信息,包括各种IT系统生成的日志,解决半结构化的数据带来的挑战,可以解决半结构化数据的挑战。占数据总量大概80%左右的数据被称之为非结构化数据,图片、视频、语音、自然语言的文本,为什么这些数据会占到80%?微信上发一条信息,今天手机上拍一张照片是几兆,非结构化数据的总量非常巨大,过去数字化转型的阶段,把图片、视频、语音、自然语言转成数据资产,存储到IT系统中,如果我想要从中挖掘更多的业务和价值,可以为我们带来更多的创新服务,这是非常困难的。
近几年深度学习的发展,非常感谢先驱为我们做了很多好用的模型和算法,他们可以将非结构化的数据转化成计算机比较容易处理的信息,通常来说是量型的信息,将非结构数据的处理变成一种对上量计算和搜索的过程。

有人认为上量数据是中间结果,可能是图片的中间结果,最终要做一些图片的分类。深度学习的场景中,传统的机器学习场景中有一个术语叫做特征工程,发挥数据科学家的经验、技能,去对数据进行筛选、清洗,结合自己的经验和知识形成一些特征。
深度学习要注重另外一个术语叫做特征学习,所有的特征是通过数据科学家、数据工程师的经验和知识,通过人为的因素生成,不是通过模型学习出来的,所以从这个角度来讲,量并不仅仅只是非结构数据处理的中间结果,上量在特征处理的场景下就是非结构数据经过深度学习模型加工之后的知识表达,是一种新型知识的表达,所以构建数据服务是非常重要的部分。
现在AI应用中,为什么要对数据提供服务?究竟看到了什么样的问题?基于流的AI应用,怎么样理解?通过模型、框架,我们可以为视频数据构建操作流,有的是形成一些图片,经过CDA的模型转换成特征的信息,特征的向量。因为它是一个视频,视频可能蕴含着声音的信息,可以声音提取出来形成一些模型的转换,特征的向量,还有一些其他的标签,不论是人工的标签,还是其他的标签,都可以附加,为视频数据加载一些标签的信息。我们发现,整个模式是比较灵活的,需要什么样的结果,需要什么样的操作,就建什么样的python,每个流水线可能都是端到端的应用,从最原始的一段非结构数据,最后会衍生出不同端到端的应用中都散落一点点的数据片断。
基于这个因素来考虑的话,我们认为有必要为这些非常零散的、散落在各个不同角落的数据提供整体的、完整的非结构数据服务。从这张图上我们把刚才基于流式的AI应用换一个角度看,用最传统的IT系统层次型的视角看的话,这上面是输入,我们原始的非结构化数据,首先会经过模型推理,模型推理这层主要负责的工作是把我们的模型做高效的、实时的Service,这不是容易的工作,我们可以找到比较好的工具或是框架。Google想做TensorFlow,通过特征学习的方式,把非结构化数据,转化成特征向量,我们可以在数据这层为这些所有的特征向量做集中的数据服务。
一部分非结构数据作为原始的存储可以放在对象存储中,提取出来的特征信息可以放在我们想要构建的项目中,为特征向量提供一些基础的服务。其实不单单是向量一块的内容,其实它包含了四个部分:一是最基础的向量,向量包含了稀疏性的向量、稠密型的向量,从现在的角度来讲对于稠密型的向量支持比较好,稀疏向量在不同的场景下的支持和操作的要求都不太一样,后面的分享例子中可以看到,稀疏向量主要是化学领域的化合物分子的结构稀疏向量。
除了向量之外,刚才讲的标签型的数据和标量型的数据,这个月的版本中会把标量数据的功能加入进去,剩下的是一些业务层更紧密,包括多模态的搜索以及作为的结果要进行集中的重新打分过程,都会在我们后续的版本中不停的迭代加入到项目中来。
大家从刚才的介绍中有点理解向量会是新型的数据,我们需要提供专门的服务,接下来的问题是,已经有了这么多的数据库,有了通用计算框架,为什么不可以把向量的功能、向量的计算附着在数据库、通用的计算框架上?为什么需要单独的新型基础组件为向量提供服务?还有数字的序列,向量和数字之间,通常会计算向量之间的相似度,我这边给的例子是计算Operation距离的例子,向量计算通常会是高性能计算的场景,上午我听AI芯片专场,清华大学的教授介绍他们做计算存储一体化新型的AI芯片,就是为了解决速度不够的问题,向量场景就是计算和双密集的场景。
第二个不同,两个数字之间可以比较大小,海量的数据构建索引的话,我们可以用这种离疏型的方式构建高效的索引,向量的场景中,因为两个向量中没有大小的关系,只有三个向量、ABC三个向量才能按照A向量和B向量比较像还是和C向量比较像,完全没有办法使用传统树形结构构建高效的索引,向量的计算或是搜索技术,我给了两个例子,一个是左边基于空间划分,会有一些小的空间搜索的时候寻找、选取一些子空间,这是我们不在全量空间中寻找,而是在子空间寻找我们想要的空间,它是近似的搜索,可以极大减少搜索的数量,提升搜索的速度。
异构计算的部分,现在的计算资源是比较多的,我们的项目中,向量搜索中也用到不同的业务计算的资源,最好的是X86的芯片,上面也有SSE的指令集指令,可以更好的适配各大不同的X86的芯片,可以充分发挥X86芯片的算力。另外一部分是在GPU上,一个项目带GPU和不带GPU的代码量是不一样的。ARM这块,主要是支持ARM86架构的芯片。感谢鹏城实验室提供鲲鹏的测试环境,我们应在鲲鹏上做过验证,包括和金山云合作的时候,也在Loogson上一些试验,这是关于异构计算的部分。
我们处理引擎部分,算法的部分引用并改进了比较成熟的算法库,开源项目接触很多的客户,索引我们集成在搜索的算法部分中,这些其他的Sensor部分我们正在开发的过程中,8月15日我们会把向量、标量混合的搜索部分补上。
蓝色部分是关于数据模拟的部分,要做为向量服务的数据库、搜索引擎。数据管理是非常重要的部分,怎么样支持更大的数据量,包括支持高速的流式加载的场景,流式要求比传统数据大得多,比如说视频处理的场景,大家可以想象,视频处理的场景,一个摄像拍摄视频的话,可以产生24帧到30帧的数据,哪怕截取关键帧、保留关键帧的操作,一秒进入三幅图片、三条数据,100个摄象头,1000个摄象头,包括在偏向于To C端的场景,一些智能客服,现在当你打开淘宝、京东和客服聊天,大概率或基本上碰不到真实的客服,客户问的问题可以转成向量数据发送到后台的搜索部分进行匹配和交互,实时注入的要求比一般我们想象中的大得多,如何支持流式的场景也是我们在数据服务中需要解决的问题。
最后是关于SDK,本身是C++的项目,C++的SDK、python的SDK等。这是在分布式的场景下,我们提供分布式的代理,向量虽然是计算和IO密集的场景,它相对简单一些,很容易做一些分布式的扩展,有点类似于传统的分布式的场景,可以在多个节点进行一部分的数据量交汇,形成一定的结果。
向量不会像数据库有TPC,但是也有开源界比较公认的,其实有三位开发者一起,这是AWS的云服务器上的测试,因为这个测试是ANN原生的测试,单线程的测试,多线程的测试在网站上是可以找到的,包括单线程测试也可以在ANN的网站上找到。
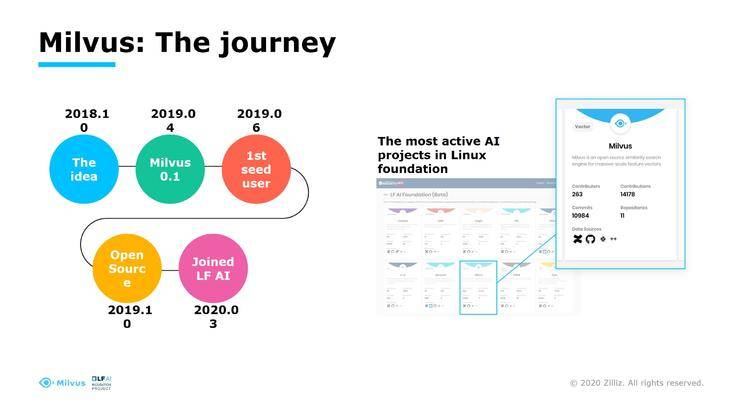
这是我们项目的开源历程,我们从2018年10月份有一个初始的想法,当时我们有一个结构化的数据库解决向量的问题,后来发现非常的痛苦,应该为向量构建专门的数据服务,我们是在去年4月份发布的0.1的版本,当时没有开源,0.1版本非常粗糙,我们找到第一个种子用户,种子用户和我们有同一个投资人,愿意接纳新兴的事物和概念,经过打磨觉得自己差不多的情况下,我们去年8月份先把我们的案例放在GitHub上看大家的反映,反响不错3月份加入LF基金会进行孵化,我们基金会属于开发相对比较活跃的项目,我们也是每个月会做一些迭代、做一些Bug的修复,有的时候是大功能、小功能的引入。
这是我们现在开源的状况,这是之前的状态,数字会有一些变化,commits5.3K,已知的用户200多家。开源项目很大的问题是,一个公司会做一些PR的文章,记者和编辑会说你今天报道的东西我们今天也有用。
去年10月份开源到现在,其实是比较年轻的项目,最核心的两点是,整个项目上来讲,比较容易使用,相对来说硬件成本比较低,这是大家接受这个项目最重要的原因。后面我会跟大家分享真实的案例。
大家知道WPS是一个办公软件,在微信上做了智能型的助手,很多自然语言的文本是从人民网、新华社拿过来的,也会有一些社区的数据,通过他的模型加工之后,最终他的文本向量会汇总,当用户发起写作需求的时候,也会根据模型进行进一步的加工,通过向量的技术,将文章的初稿组合起来以后交还给用户,微信小程序试用一下还是蛮有趣的,大家有兴趣可以试用一下,这就是我们分享非常简单的、直观的架构,中间是模型与算法发挥的作用,最下面是我们的数据服务提供的支撑。
我认为AI的转型始之于算法,继之于服务。当你打开小米浏览器会有新闻推荐,很多的浏览器都有新闻推荐的工作,这上面小米浏览器的算法工程师,也是用它做新闻相关的推荐工作,日中的芯片标题放在Milvus,也有一些实时的流,比较热门的新闻也会有一些流,搜集进来,经过模型的转换,用户打开浏览器的时候,会根据行为召回热门新闻推荐中呈现出。
接下来是企查查的例子,他们有5500万张的中国企业商标的图片,他们对图片的收集非常的完整,他们也希望为自己的用户提供更好的服务。怎么样去让用户可以搜这些商标图片?他们原来想了很多的方法,效果都不是特别理想,当中有多种原因,一些是算法的原因,一些是实际部署的成本。大家可以想一想当你提供一个商标图片搜索的功能以后,究竟会为企查查带来多少收费用户,会带来多少新的用户,因为这一个功能而成为你的付费用户?这个问题是困扰所有技术公司最大的问题,当你要做一个AI功能的时候,你要投入算法工程师,你要投入硬件的资源。但你的收益不是可以量化的,你知道AI的功能以后,可以提升产品的科技感,可以更有吸引力,但是很难用虚的东西说服你的老板投这个东西,对他们来讲,最重要的是硬件的成本以及上手难度,通过Milvus,他们把模型放在端侧进行部署。
子结构的搜索,当你给出一个片断,完整的分子式去搜索他所有包含的片断,当你给出一个片断搜索可能包含他的超结构的分子,公开数据是可以达到8亿的分子式,通过Milvus承载搜索引擎,单台机上只需要500毫秒,AI的算力不单单是硬件的发展,同时也是软件算法的发展,软件算法的发展,从算法的迭代上得到的好处可能比使用新型硬件带来的更多。
最后这页是我们的项目相关的链接,我们项目的网站,公司的公众号二维码,大家有兴趣可以上去看一下,我们也在网站上提供一些非常有趣、简单的DEMO,DEMO的代码上也在GitHbu上,我今天的分享就到这里,谢谢。
雷锋网
雷锋网原创文章,未经授权禁止转载。详情见转载须知。

