传统运维管理的人工及被动响应方式,已经无法支撑数字化业务灵活、快速的发展,要靠智能运维(AIOps)能力来获得数据分析和决策支持。而从传统ITOM到智能运维的演进过程中,需要一系列关键技术的支撑。本文试图就智能运维落地过程所需关键技术点进行概要说明。

图片来源:Gartner
从智能运维的平台架构来看,可抽象为几个层面:数据采集层、数据汇聚层、数据存储层、建模应用层、分析学习层、应用反馈层。这是一个非常理想的层次划分,但在智能运维实践落地过程中,却存在着诸多坑壑,需要我们正视和解决。
数据采集与传输
运维数据的产生和采集来自于ITOM监控工具集,通常包括:基础服务可用性和性能监控、网络性能监测与诊断、中间件服务可用性和性能监控、应用性能管理、系统运行日志管理、IT资产管理、IT服务支持管理等。
这些基础监控工具采集的运行状态数据和运行性能数据,需要具备足够存量的数据和数据增量;以及足够的数据维度覆盖度(时间维度、空间维度、系统级维度、应用级维度等)才能进行建模利用。与此同时,运维数据的时效性强、多维数据源割裂采集的现状、以及如何在后续建模过程中进行多维数据的高效关联,因此智能运维平台对数据采集层提出以下技术要求:
• 跨平台、跨语言栈、高兼容性的多模式统一采集质量标准;
• 兼容多种非容器化与容器化运行环境;
• 一致的维度关联属性;
• 在资源占用、数据压缩比、时效性之间可权衡、可调节的传送机制;
• 可靠的熔断和止损机制;
• 易于部署和维护、统一的配置和任务管理。
数据汇聚、存储与建模
数据的增量是迅猛的,或将达到网络的上行极限或磁盘的写入极限,因此对汇聚层的服务自身可用性和吞吐性能要求极高。汇聚层更像“数据湖”,提供元数据限制更为宽松的数据写入和获取途径、简易的数据清洗任务创建与管理、灵活的数据访问控制和使用行为审计、具备从原始数据的发掘中更便利的进行价值发掘、具备更敏捷的扩展特性等。
同时,在设计汇聚存储层的建设方案时,需要避免数据泥沼、无法自助建模、无法执行权限管控等困境。在智能运维实践落地时,要由一组大数据业务专家/架构师,明确地为汇聚与存储层设计一系列的能力项,这些能力项不仅要满足“数据湖”的诸多特征,还要具备便捷的开发和实施友好性,降低数据接入与抽取清洗的成本,它应该具备至少以下关键技术能力:
• 多数据源、海量数据的快速接入能力;
• 元数据提取和管理能力;
• 极其简易的、高性能的数据清洗转换能力;
• 可根据数据字典或特征算法对数据进行关键字识别、模式识别的标记能力;
• 自动的、自助的,对敏感数据进行脱敏或加密处理能力;
• 对数据质量检验并对质量标准进行归一化处置的能力;
• 数据可依据某种维度或特征进行所属和应用权限控制的能力;
• 自动的、自助的,数据建模探索能力;
• 对已建立的搜索、过滤、关联、探索模型,友好的进行数据输出能力;
• 自动的、自助的,分布式集群伸缩能力;
• 对外提供高效、敏捷数据服务的能力。
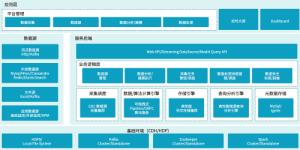
图:DODB逻辑架构(2017-2020)
云智慧专业运维数据库DODB(Digital Operation Database)正是符合上述设计目标的一款专业运维数据库,基础运行环境搭建在CDH/HDP之上,包含了HDFS、Kafka集群、Zookeeper集群以及Spark集群。
DODB可方便地进行采集任务的配置和管理,支持数百种数据源,包括日志数据采集、数据库和中间件数据性能数据采集、数十种数据库中表数据采集、数十种数据消息中间件中数据采集等,支持集群部署、中心化配置管理、状态自监控与高效熔断等能力,支持高可扩展性,同时巧妙的解决了数据泥沼和无法自助建模的困扰。
算法体系建设
在智能运维(AIOps)落地实践中,算法体系的建设是至关重要的一个环节。算法体系建设方面,应从三个角度来去考虑实现思路:
• 感知:如异常检测、趋势预测、问题定位、智能告警;
• 决策:如弹性扩缩容策略、告警策略;
• 执行:如扩缩容执行、资源调度执行。
智能分析系统将感知、决策、执行三个角度落地到智能运维解决方案中,形成发现问题、产生告警事件、算法模式定位问题、根据分析结果解决问题的闭环功能。
因此,智能分析平台应具备交互式建模功能、算法库、样本库、数据准备、可扩展的底层框架支持、数据分析探索、模型评估、参数及算法搜索、场景模型、实验报告、模型的版本管理、模型部署应用等功能或模块。
云智慧智能分析平台DOIA(Digital Operation Intelligent Analysis),依托DODB专业运维数据库提供的基础大数据资源,赋予智能运维的能力,包括动态基线、异常检测、根因分析、智能合并、智能故障预测、知识工程等。智能分析平台是产出算法,满足跨平台、多样化的客户现场环境,从最小单元化部署到大规模集群式部署的可行性方案。
算法和数据的工程融合
在智能运维(AIOps)平台落地的实践中,算法和数据的融合,第一步是数据的采集和汇聚,通过前文介绍的关键技术,我们已经获得了质量标准归一化的、经过了提取和转换的、时间/空间/业务维度标记清楚的数据,需要补充的是数据预处理相关的核心要点。
1、数据预处理
在数据挖掘中,海量原始数据中存在大量不完整(有缺失值)、不一致或有异常的数据,严重影响到数据挖掘建模的执行效率,甚至可能导致挖掘结果的偏差。数据预处理的目的是提高数据质量,从而提升数据挖掘的质量。方法包括数据清洗、数据集成和转换,以及数据归约。
通过数据预处理,可以去掉数据中的噪音,纠正不一致;数据集成将数据由多个源合并成一致的数据存储,如数据仓储或数据立方;数据变换(如规范化)也可以使用,例如规范化可以改进涉及距离度量的挖掘算法的精度和有效性;数据规约可以通过合并、删除冗余特征或聚类来压缩数据。这些数据处理技术在数据挖掘之前使用,可以大大提高数据挖掘模式的质量,降低实际挖掘所需要的时间。
需要注意,有些算法对异常值非常敏感。任何依赖均值/方差的算法都对离群值敏感,因为这些统计量受极值的影响极大。另一方面,一些算法对离群点具有更强的鲁棒性。数据分析中的描述性统计分析认为:当我们面对大量信息的时候,经常会出现数据越多,事实越模糊的情况,因此我们需要对数据进行简化,描述统计学就是用几个关键的数字来描述数据集的整体情况。
2、算法工程集成
在智能运维(AIOps)算法分析系统中,不同算法对应不同的适配场景,需要根据数据特征模式来选择合适的算法应用。如指标异常算法的应用:针对周期稳定性数据,我们采取动态极限的模型;针对周期不不稳定的数据,采⽤频域分析的模型;针对稳定性的数据采⽤极限阈值判断的模型。通过模型选择的算法,对不同的数据的模型进行适配,达到最优的效果。
因此,想要以开箱即用的方式、采用某种标准的机器学习算法直接应用,而不考虑业务特征,通常并不可行。
我们需要首先考虑该组业务指标间的关联性,如果有应用或系统间的调用链或调用拓扑供参考,这是最好不过的。如果没有调用链或拓扑,则需要先根据已知可能的业务相关性,进行曲线波动关联、回归分析等算法分析,获得极限阈值尝试得到因果匹配,通过一系列的事件归集得到相关性,再对每一次反馈进行适应,尝试自动匹配更为准确的算法和参数,才可能达到期望的异常检测目标。
智能运维的工程化过程,是一个算法、算力与数据相结合,平台自身与业务系统反馈相结合的复杂过程。在与业务场景结合的前提下,灵活的算力组织、高效的数据同步、可插拔的服务化、模型应用过程中的高精度与高速度,是AI工程化本身的核心诉求。
总结和展望
智能运维(AIOps)落地的过程中的坑非常多,这是云智慧过去几年大量行业实践得到的真实体验。它对数据平台搭建、数据采集与传输、数据汇聚、存储与建模、数据计算、AI体系化、场景与工程化融合等方面提出了极其苛刻的要求,需要更专业的、更高质量标准的运维数据库,还需要一支强有力的分析、架构和开发团队支撑,才能真正带来生产力的提高。(作者:高驰涛)
