еүҚеҮ ж—ҘпјҢжңәеҷЁд№Ӣеҝғзј–иҜ‘д»Ӣз»ҚдәҶгҖҠд»Һйӣ¶ејҖе§Ӣ PyTorch йЎ№зӣ®пјҡYOLO v3 зӣ®ж ҮжЈҖжөӢе®һзҺ°гҖӢзҡ„еүҚ 3 йғЁеҲҶпјҢд»Ӣз»ҚдәҶ YOLO зҡ„е·ҘдҪңеҺҹзҗҶгҖҒеҲӣе»ә YOLO зҪ‘з»ңеұӮзә§е’Ңе®һзҺ°зҪ‘з»ңзҡ„еүҚеҗ‘дј ж’ӯзҡ„ж–№жі•гҖӮжң¬ж–ҮеҢ…еҗ«дәҶиҜҘж•ҷзЁӢзҡ„еҗҺйқўдёӨдёӘйғЁеҲҶпјҢе°Ҷд»Ӣз»ҚгҖҢзҪ®дҝЎеәҰйҳҲеҖји®ҫзҪ®е’ҢйқһжһҒеӨ§еҖјжҠ‘еҲ¶гҖҚд»ҘеҸҠгҖҢи®ҫи®Ўиҫ“е…Ҙе’Ңиҫ“еҮәжөҒзЁӢгҖҚзҡ„ж–№жі•гҖӮжҖ»дҪ“иҖҢиЁҖпјҢжң¬ж•ҷзЁӢзҡ„зӣ®зҡ„жҳҜдҪҝз”Ё PyTorch е®һзҺ°еҹәдәҺ YOLO v3 зҡ„зӣ®ж ҮжЈҖжөӢеҷЁпјҢеҗҺиҖ…жҳҜдёҖз§Қеҝ«йҖҹзҡ„зӣ®ж ҮжЈҖжөӢз®—жі•гҖӮ
жң¬ж•ҷзЁӢдҪҝз”Ёзҡ„д»Јз ҒйңҖиҰҒиҝҗиЎҢеңЁ Python 3.5 е’Ң PyTorch 0.3 зүҲжң¬д№ӢдёҠгҖӮдҪ еҸҜд»ҘеңЁд»ҘдёӢй“ҫжҺҘдёӯжүҫеҲ°жүҖжңүд»Јз Ғпјҡhttps://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch
жүҖйңҖиғҢжҷҜзҹҘиҜҶ
1.жң¬ж•ҷзЁӢ 1-3 йғЁеҲҶ
2.дәҶи§Ј PyTorch еҹәжң¬е·ҘдҪңж–№ејҸпјҢеҢ…жӢ¬дҪҝз”Ё nn.ModuleгҖҒnn.Sequential е’Ң torch.nn.parameter зұ»еҲӣе»әиҮӘе®ҡд№үжһ¶жһ„зҡ„ж–№ејҸ
3.NumPy еҹәжң¬зҹҘиҜҶ
4.OpenCV еҹәжң¬зҹҘиҜҶ
еҰӮжһңдҪ зјәе°‘иҝҷдәӣйў„еӨҮзҹҘиҜҶпјҢеҸҜеҸӮйҳ…ж–Үжң«жү©еұ•йҳ…иҜ»йғЁеҲҶдәҶи§ЈгҖӮ
зҪ®дҝЎеәҰйҳҲеҖји®ҫзҪ®е’ҢйқһжһҒеӨ§еҖјжҠ‘еҲ¶
еңЁеүҚйқў 3 йғЁеҲҶдёӯпјҢжҲ‘们已з»Ҹжһ„е»әдәҶдёҖдёӘиғҪдёәз»ҷе®ҡиҫ“е…ҘеӣҫеғҸиҫ“еҮәеӨҡдёӘзӣ®ж ҮжЈҖжөӢз»“жһңзҡ„жЁЎеһӢгҖӮе…·дҪ“жқҘиҜҙпјҢжҲ‘们зҡ„иҫ“еҮәжҳҜдёҖдёӘеҪўзҠ¶дёә B x 10647 x 85 зҡ„еј йҮҸпјӣе…¶дёӯ B жҳҜжҢҮдёҖжү№пјҲbatchпјүдёӯеӣҫеғҸзҡ„ж•°йҮҸпјҢ10647 жҳҜжҜҸдёӘеӣҫеғҸдёӯжүҖйў„жөӢзҡ„иҫ№з•ҢжЎҶзҡ„ж•°йҮҸпјҢ85 жҳҜжҢҮиҫ№з•ҢжЎҶеұһжҖ§зҡ„ж•°йҮҸгҖӮ
дҪҶжҳҜпјҢжӯЈеҰӮ第 1 йғЁеҲҶжүҖиҝ°пјҢжҲ‘们еҝ…йЎ»дҪҝжҲ‘们зҡ„иҫ“еҮәж»Ўи¶і objectness еҲҶж•°йҳҲеҖје’ҢйқһжһҒеӨ§еҖјжҠ‘еҲ¶пјҲNMSпјүпјҢд»Ҙеҫ—еҲ°еҗҺж–ҮжүҖиҜҙзҡ„гҖҢзңҹе®һпјҲtrueпјүгҖҚжЈҖжөӢз»“жһңгҖӮиҰҒеҒҡеҲ°иҝҷдёҖзӮ№пјҢжҲ‘们е°ҶеңЁ util.py ж–Ү件дёӯеҲӣе»әдёҖдёӘеҗҚдёә write_results зҡ„еҮҪж•°гҖӮ
иҜҘеҮҪж•°зҡ„иҫ“е…Ҙдёәйў„жөӢз»“жһңгҖҒзҪ®дҝЎеәҰпјҲobjectness еҲҶж•°йҳҲеҖјпјүгҖҒnum_classesпјҲжҲ‘们иҝҷйҮҢжҳҜ 80пјүе’Ң nms_confпјҲNMS IoU йҳҲеҖјпјүгҖӮ
зӣ®ж ҮзҪ®дҝЎеәҰйҳҲеҖј
жҲ‘们зҡ„йў„жөӢеј йҮҸеҢ…еҗ«жңүе…і B x 10647 иҫ№з•ҢжЎҶзҡ„дҝЎжҒҜгҖӮеҜ№дәҺжңүдҪҺдәҺдёҖдёӘйҳҲеҖјзҡ„ objectness еҲҶж•°зҡ„жҜҸдёӘиҫ№з•ҢжЎҶпјҢжҲ‘们е°Ҷе…¶жҜҸдёӘеұһжҖ§зҡ„еҖјпјҲиЎЁзӨәиҜҘиҫ№з•ҢжЎҶзҡ„дёҖж•ҙиЎҢпјүйғҪи®ҫдёәйӣ¶гҖӮ
жү§иЎҢйқһжһҒеӨ§еҖјжҠ‘еҲ¶
жіЁпјҡжҲ‘еҒҮи®ҫдҪ е·Із»ҸзҗҶи§Ј IoUпјҲIntersection over unionпјүе’ҢйқһжһҒеӨ§еҖјжҠ‘еҲ¶пјҲNon-maximum suppressionпјүзҡ„еҗ«д№үдәҶгҖӮеҰӮжһңдҪ иҝҳдёҚзҗҶи§ЈпјҢиҜ·еҸӮйҳ…ж–Үжң«жҸҗдҫӣзҡ„й“ҫжҺҘгҖӮ
жҲ‘们зҺ°еңЁжӢҘжңүзҡ„иҫ№з•ҢжЎҶеұһжҖ§жҳҜз”ұдёӯеҝғеқҗж Үд»ҘеҸҠиҫ№з•ҢжЎҶзҡ„й«ҳеәҰе’Ңе®ҪеәҰеҶіе®ҡзҡ„гҖӮдҪҶжҳҜпјҢдҪҝз”ЁжҜҸдёӘжЎҶзҡ„дёӨдёӘеҜ№и§’еқҗж ҮиғҪжӣҙиҪ»жқҫең°и®Ўз®—дёӨдёӘжЎҶзҡ„ IoUгҖӮжүҖд»ҘпјҢжҲ‘们еҸҜд»Ҙе°ҶжҲ‘们зҡ„жЎҶзҡ„ (дёӯеҝғ x, дёӯеҝғ y, й«ҳеәҰ, е®ҪеәҰ) еұһжҖ§иҪ¬жҚўжҲҗ (е·ҰдёҠи§’ x, е·ҰдёҠи§’ y, еҸідёӢи§’ x, еҸідёӢи§’ y)гҖӮ
жҜҸеј еӣҫеғҸдёӯзҡ„гҖҢзңҹе®һгҖҚжЈҖжөӢз»“жһңзҡ„ж•°йҮҸеҸҜиғҪеӯҳеңЁе·®ејӮгҖӮжҜ”еҰӮпјҢдёҖдёӘеӨ§е°Ҹдёә 3 зҡ„ batch дёӯжңү 1гҖҒ2гҖҒ3 иҝҷ 3 еј еӣҫеғҸпјҢе®ғ们еҗ„иҮӘжңү 5гҖҒ2гҖҒ4 дёӘгҖҢзңҹе®һгҖҚжЈҖжөӢз»“жһңгҖӮеӣ жӯӨпјҢдёҖж¬ЎеҸӘиғҪе®ҢжҲҗдёҖеј еӣҫеғҸзҡ„зҪ®дҝЎеәҰйҳҲеҖји®ҫзҪ®е’Ң NMSгҖӮд№ҹе°ұжҳҜиҜҙпјҢжҲ‘们дёҚиғҪе°ҶжүҖж¶үеҸҠзҡ„ж“ҚдҪңеҗ‘йҮҸеҢ–пјҢиҖҢдё”еҝ…йЎ»еңЁйў„жөӢзҡ„第дёҖдёӘз»ҙеәҰпјҲеҢ…еҗ«дёҖдёӘ batch дёӯеӣҫеғҸзҡ„зҙўеј•пјүдёҠеҫӘзҺҜгҖӮ
еҰӮеүҚжүҖиҝ°пјҢwrite ж ҮзӯҫжҳҜз”ЁдәҺжҢҮзӨәжҲ‘们е°ҡжңӘеҲқе§ӢеҢ–иҫ“еҮәпјҢжҲ‘们е°ҶдҪҝз”ЁдёҖдёӘеј йҮҸжқҘ收йӣҶж•ҙдёӘ batch зҡ„гҖҢзңҹе®һгҖҚжЈҖжөӢз»“жһңгҖӮ
иҝӣе…ҘеҫӘзҺҜеҗҺпјҢжҲ‘们еҶҚжӣҙжё…жҘҡең°иҜҙжҳҺдёҖдёӢгҖӮжіЁж„ҸжҜҸдёӘиҫ№з•ҢжЎҶиЎҢйғҪжңү 85 дёӘеұһжҖ§пјҢе…¶дёӯ 80 дёӘжҳҜзұ»еҲ«еҲҶж•°гҖӮжӯӨж—¶пјҢжҲ‘们еҸӘе…іеҝғжңүжңҖеӨ§еҖјзҡ„зұ»еҲ«еҲҶж•°гҖӮжүҖд»ҘпјҢжҲ‘们移йҷӨдәҶжҜҸдёҖиЎҢзҡ„иҝҷ 80 дёӘзұ»еҲ«еҲҶж•°пјҢ并且иҪ¬иҖҢеўһеҠ дәҶжңүжңҖеӨ§еҖјзҡ„зұ»еҲ«зҡ„зҙўеј•д»ҘеҸҠйӮЈдёҖзұ»еҲ«зҡ„зұ»еҲ«еҲҶж•°гҖӮ
и®°еҫ—жҲ‘们е°Ҷ object зҪ®дҝЎеәҰе°ҸдәҺйҳҲеҖјзҡ„иҫ№з•ҢжЎҶиЎҢи®ҫдёәйӣ¶дәҶеҗ—пјҹи®©жҲ‘们ж‘Ҷи„ұе®ғ们гҖӮ
е…¶дёӯзҡ„ try-except жЁЎеқ—зҡ„зӣ®зҡ„жҳҜеӨ„зҗҶж— жЈҖжөӢз»“жһңзҡ„жғ…еҶөгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们дҪҝз”Ё continue жқҘи·іиҝҮеҜ№жң¬еӣҫеғҸзҡ„еҫӘзҺҜгҖӮ
зҺ°еңЁпјҢи®©жҲ‘们иҺ·еҸ–дёҖеј еӣҫеғҸдёӯжүҖжЈҖжөӢеҲ°зҡ„зұ»еҲ«гҖӮ
еӣ дёәеҗҢдёҖзұ»еҲ«еҸҜиғҪдјҡжңүеӨҡдёӘгҖҢзңҹе®һгҖҚжЈҖжөӢз»“жһңпјҢжүҖд»ҘжҲ‘们дҪҝз”ЁдёҖдёӘеҗҚеҸ« unique зҡ„еҮҪж•°жқҘиҺ·еҸ–д»»ж„Ҹз»ҷе®ҡеӣҫеғҸдёӯеӯҳеңЁзҡ„зұ»еҲ«гҖӮ
然еҗҺпјҢжҲ‘们жҢүз…§зұ»еҲ«жү§иЎҢ NMSгҖӮ
дёҖж—ҰжҲ‘们иҝӣе…ҘеҫӘзҺҜпјҢжҲ‘们иҰҒеҒҡзҡ„第дёҖ件дәӢе°ұжҳҜжҸҗеҸ–зү№е®ҡзұ»еҲ«пјҲз”ЁеҸҳйҮҸ cls иЎЁзӨәпјүзҡ„жЈҖжөӢз»“жһңгҖӮ
жіЁж„ҸпјҢд»ҘдёӢд»Јз ҒеңЁеҺҹе§Ӣд»Јз Ғж–Ү件дёӯжңү 3 ж јзј©иҝӣпјҢдҪҶеӣ дёәйЎөйқўз©әй—ҙжңүйҷҗпјҢиҝҷйҮҢжІЎжңүзј©иҝӣгҖӮ
зҺ°еңЁпјҢжҲ‘们жү§иЎҢ NMSгҖӮ
иҝҷйҮҢпјҢжҲ‘们дҪҝз”ЁдәҶеҮҪж•° bbox_iouгҖӮ第дёҖдёӘиҫ“е…ҘжҳҜиҫ№з•ҢжЎҶиЎҢпјҢиҝҷжҳҜз”ұеҫӘзҺҜдёӯзҡ„еҸҳйҮҸ i зҙўеј•зҡ„гҖӮbbox_iou зҡ„第дәҢдёӘиҫ“е…ҘжҳҜеӨҡдёӘиҫ№з•ҢжЎҶиЎҢжһ„жҲҗзҡ„еј йҮҸгҖӮbbox_iou еҮҪж•°зҡ„иҫ“еҮәжҳҜдёҖдёӘеј йҮҸпјҢе…¶дёӯеҢ…еҗ«йҖҡиҝҮ第дёҖдёӘиҫ“е…Ҙд»ЈиЎЁзҡ„иҫ№з•ҢжЎҶдёҺ第дәҢдёӘиҫ“е…Ҙдёӯзҡ„жҜҸдёӘиҫ№з•ҢжЎҶзҡ„ IoUгҖӮ
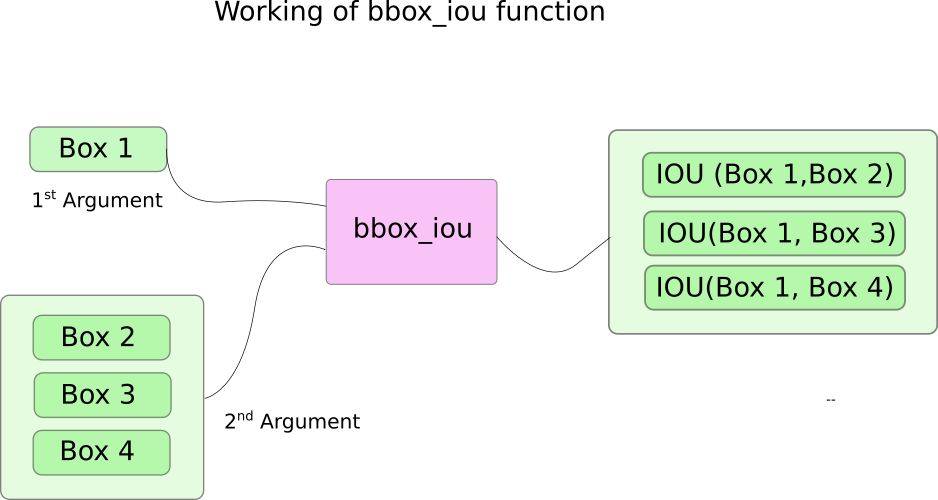
еҰӮжһңжҲ‘们жңү 2 дёӘеҗҢж ·зұ»еҲ«зҡ„иҫ№з•ҢжЎҶдё”е®ғ们зҡ„ IoU еӨ§дәҺдёҖдёӘйҳҲеҖјпјҢйӮЈд№Ҳе°ұеҺ»жҺүе…¶дёӯзұ»еҲ«зҪ®дҝЎеәҰиҫғдҪҺзҡ„йӮЈдёӘгҖӮжҲ‘们已з»ҸеҜ№иҫ№з•ҢжЎҶиҝӣиЎҢдәҶжҺ’еәҸпјҢе…¶дёӯжңүжӣҙй«ҳзҪ®дҝЎеәҰзҡ„еңЁдёҠйқўгҖӮ
еңЁеҫӘзҺҜйғЁеҲҶпјҢдёӢйқўзҡ„д»Јз Ғз»ҷеҮәдәҶжЎҶзҡ„ IoUпјҢе…¶дёӯйҖҡиҝҮ i зҙўеј•жүҖжңүзҙўеј•жҺ’еәҸй«ҳдәҺ i зҡ„иҫ№з•ҢжЎҶгҖӮ
жҜҸж¬Ўиҝӯд»Јж—¶пјҢеҰӮжһңжңүиҫ№з•ҢжЎҶзҡ„зҙўеј•еӨ§дәҺ i дё”жңүеӨ§дәҺйҳҲеҖј nms_thresh зҡ„ IoUпјҲдёҺзҙўеј•дёә i зҡ„жЎҶпјүпјҢйӮЈд№Ҳе°ұеҺ»жҺүйӮЈдёӘзү№е®ҡзҡ„жЎҶгҖӮ
иҝҳиҰҒжіЁж„ҸпјҢжҲ‘们已з»Ҹе°Ҷз”ЁдәҺи®Ўз®— ious зҡ„д»Јз Ғж”ҫеңЁдәҶдёҖдёӘ try-catch жЁЎеқ—дёӯгҖӮиҝҷжҳҜеӣ дёәиҝҷдёӘеҫӘзҺҜеңЁи®ҫи®ЎдёҠжҳҜдёәдәҶиҝҗиЎҢ idx ж¬Ўиҝӯд»ЈпјҲimage_pred_class дёӯзҡ„иЎҢж•°пјүгҖӮдҪҶжҳҜпјҢеҪ“жҲ‘们继з»ӯеҫӘзҺҜж—¶пјҢдёҖдәӣиҫ№з•ҢжЎҶеҸҜиғҪдјҡд»Һ image_pred_class 移йҷӨгҖӮиҝҷж„Ҹе‘ізқҖпјҢеҚідҪҝеҸӘд»Һ image_pred_class дёӯ移йҷӨдәҶдёҖдёӘеҖјпјҢжҲ‘们д№ҹдёҚиғҪжңү idx ж¬Ўиҝӯд»ЈгҖӮеӣ жӯӨпјҢжҲ‘们еҸҜиғҪдјҡе°қиҜ•зҙўеј•дёҖдёӘиҫ№з•Ңд№ӢеӨ–зҡ„еҖјпјҲIndexErrorпјүпјҢзүҮзҠ¶зҡ„ image_pred_class[i+1:] еҸҜиғҪдјҡиҝ”еӣһдёҖдёӘз©әеј йҮҸпјҢд»ҺиҖҢжҢҮе®ҡи§ҰеҸ‘ ValueError зҡ„йҮҸгҖӮжӯӨж—¶пјҢжҲ‘们еҸҜд»ҘзЎ®е®ҡ NMS дёҚиғҪиҝӣдёҖжӯҘ移йҷӨиҫ№з•ҢжЎҶпјҢ然еҗҺи·іеҮәеҫӘзҺҜгҖӮ
и®Ўз®— IoU
иҝҷйҮҢжҳҜ bbox_iou еҮҪж•°гҖӮ
еҶҷеҮәйў„жөӢ
write_results еҮҪж•°иҫ“еҮәдёҖдёӘеҪўзҠ¶дёә Dx8 зҡ„еј йҮҸпјӣе…¶дёӯ D жҳҜжүҖжңүеӣҫеғҸдёӯзҡ„гҖҢзңҹе®һгҖҚжЈҖжөӢз»“жһңпјҢжҜҸдёӘйғҪз”ЁдёҖиЎҢиЎЁзӨәгҖӮжҜҸдёҖдёӘжЈҖжөӢз»“жһңйғҪжңү 8 дёӘеұһжҖ§пјҢеҚіпјҡиҜҘжЈҖжөӢз»“жһңжүҖеұһзҡ„ batch дёӯеӣҫеғҸзҡ„зҙўеј•гҖҒ4 дёӘи§’зҡ„еқҗж ҮгҖҒobjectness еҲҶж•°гҖҒжңүжңҖеӨ§зҪ®дҝЎеәҰзҡ„зұ»еҲ«зҡ„еҲҶж•°гҖҒиҜҘзұ»еҲ«зҡ„зҙўеј•гҖӮ
еҰӮд№ӢеүҚдёҖж ·пјҢжҲ‘们没жңүеҲқе§ӢеҢ–жҲ‘们зҡ„иҫ“еҮәеј йҮҸпјҢйҷӨйқһжҲ‘们жңүиҰҒеҲҶй…Қз»ҷе®ғзҡ„жЈҖжөӢз»“жһңгҖӮдёҖж—Ұе…¶иў«еҲқе§ӢеҢ–пјҢжҲ‘们е°ұе°ҶеҗҺз»ӯзҡ„жЈҖжөӢз»“жһңдёҺе®ғиҝһжҺҘиө·жқҘгҖӮжҲ‘们дҪҝз”Ё write ж ҮзӯҫжқҘиЎЁзӨәеј йҮҸжҳҜеҗҰеҲқе§ӢеҢ–дәҶгҖӮеңЁзұ»еҲ«дёҠиҝӯд»Јзҡ„еҫӘзҺҜз»“жқҹж—¶пјҢжҲ‘们е°ҶжүҖеҫ—еҲ°зҡ„жЈҖжөӢз»“жһңеҠ е…ҘеҲ°еј йҮҸиҫ“еҮәдёӯгҖӮ
еңЁиҜҘеҮҪж•°з»“жқҹж—¶пјҢжҲ‘们дјҡжЈҖжҹҘиҫ“еҮәжҳҜеҗҰе·Іиў«еҲқе§ӢеҢ–гҖӮеҰӮжһңжІЎжңүпјҢе°ұж„Ҹе‘ізқҖеңЁиҜҘ batch зҡ„д»»ж„ҸеӣҫеғҸдёӯйғҪжІЎжңүеҚ•дёӘжЈҖжөӢз»“жһңгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们иҝ”еӣһ 0гҖӮ
иҝҷйғЁеҲҶе°ұеҲ°жӯӨдёәжӯўдәҶгҖӮеңЁиҝҷйғЁеҲҶз»“жқҹж—¶пјҢжҲ‘们з»ҲдәҺжңүдәҶдёҖдёӘеј йҮҸеҪўејҸзҡ„йў„жөӢз»“жһңпјҢе…¶дёӯд»ҘиЎҢзҡ„еҪўејҸеҲ—еҮәдәҶжҜҸдёӘйў„жөӢгҖӮзҺ°еңЁиҝҳеү©дёӢпјҡеҲӣйҖ дёҖдёӘд»ҺзЈҒзӣҳиҜ»еҸ–еӣҫеғҸзҡ„иҫ“е…ҘжөҒзЁӢпјҢи®Ўз®—йў„жөӢз»“жһңпјҢеңЁеӣҫеғҸдёҠз»ҳеҲ¶иҫ№з•ҢжЎҶпјҢ然еҗҺеұ•зӨә / еҶҷе…ҘиҝҷдәӣеӣҫеғҸгҖӮиҝҷжҳҜдёӢдёҖйғЁеҲҶиҰҒд»Ӣз»Қзҡ„еҶ…е®№гҖӮ
и®ҫи®Ўиҫ“е…Ҙе’Ңиҫ“еҮәжөҒзЁӢ
еңЁиҝҷдёҖйғЁеҲҶпјҢжҲ‘们е°ҶдёәжҲ‘们зҡ„жЈҖжөӢеҷЁжһ„е»әиҫ“е…Ҙе’Ңиҫ“еҮәжөҒзЁӢгҖӮиҝҷж¶үеҸҠеҲ°д»ҺзЈҒзӣҳиҜ»еҸ–еӣҫеғҸпјҢеҒҡеҮәйў„жөӢпјҢдҪҝз”Ёйў„жөӢз»“жһңеңЁеӣҫеғҸдёҠз»ҳеҲ¶иҫ№з•ҢжЎҶпјҢ然еҗҺе°Ҷе®ғ们дҝқеӯҳеҲ°зЈҒзӣҳдёҠгҖӮжҲ‘们д№ҹдјҡд»Ӣз»ҚеҰӮдҪ•и®©жЈҖжөӢеҷЁеңЁзӣёжңәйҰҲйҖҒжҲ–и§Ҷйў‘дёҠе®һж—¶е·ҘдҪңгҖӮжҲ‘们е°Ҷеј•е…ҘдёҖдәӣе‘Ҫд»ӨиЎҢж ҮзӯҫпјҢд»ҘдҫҝиғҪдҪҝз”ЁиҜҘзҪ‘з»ңзҡ„еҗ„з§Қи¶…еҸӮж•°иҝӣиЎҢдёҖдәӣе®һйӘҢгҖӮжҺҘдёӢжқҘе°ұејҖе§Ӣеҗ§гҖӮ
жіЁпјҡиҝҷйғЁеҲҶйңҖиҰҒе®үиЈ… OpenCV 3гҖӮ
еңЁжҲ‘们зҡ„жЈҖжөӢеҷЁж–Ү件дёӯеҲӣе»әдёҖдёӘ detector.py ж–Ү件пјҢеңЁдёҠйқўеҜје…Ҙеҝ…иҰҒзҡ„еә“гҖӮ
еҲӣе»әе‘Ҫд»ӨиЎҢеҸӮж•°
еӣ дёә detector.py жҳҜжҲ‘们иҝҗиЎҢжҲ‘们зҡ„жЈҖжөӢеҷЁзҡ„ж–Ү件пјҢжүҖд»ҘжңүдёҖдәӣеҸҜд»Ҙдј йҖ’з»ҷе®ғзҡ„е‘Ҫд»ӨиЎҢеҸӮж•°дјҡеҫҲдёҚй”ҷпјҢжҲ‘дҪҝз”ЁдәҶ Python зҡ„ ArgParse жқҘеҒҡиҝҷ件дәӢгҖӮ
еңЁиҝҷдәӣеҸӮж•°дёӯпјҢйҮҚиҰҒзҡ„ж ҮзӯҫеҢ…жӢ¬ imagesпјҲз”ЁдәҺжҢҮе®ҡиҫ“е…ҘеӣҫеғҸжҲ–еӣҫеғҸзӣ®еҪ•пјүгҖҒdetпјҲдҝқеӯҳжЈҖжөӢз»“жһңзҡ„зӣ®еҪ•пјүгҖҒresoпјҲиҫ“е…ҘеӣҫеғҸзҡ„еҲҶиҫЁзҺҮпјҢеҸҜз”ЁдәҺеңЁйҖҹеәҰдёҺеҮҶзЎ®еәҰд№Ӣй—ҙзҡ„жқғиЎЎпјүгҖҒcfgпјҲжӣҝд»Јй…ҚзҪ®ж–Ү件пјүе’Ң weightfileгҖӮ
еҠ иҪҪзҪ‘з»ң
д»ҺиҝҷйҮҢдёӢиҪҪ coco.names ж–Ү件пјҡhttps://raw.githubusercontent.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch/master/data/coco.namesгҖӮиҝҷдёӘж–Ү件еҢ…еҗ«дәҶ COCO ж•°жҚ®йӣҶдёӯзӣ®ж Үзҡ„еҗҚз§°гҖӮеңЁдҪ зҡ„жЈҖжөӢеҷЁзӣ®еҪ•дёӯеҲӣе»әдёҖдёӘж–Ү件еӨ№ dataгҖӮеҰӮжһңдҪ дҪҝз”Ёзҡ„ LinuxпјҢдҪ еҸҜд»ҘдҪҝз”Ёд»ҘдёӢе‘Ҫд»Өе®һзҺ°пјҡ
然еҗҺпјҢе°Ҷзұ»еҲ«ж–Ү件иҪҪе…ҘеҲ°жҲ‘们зҡ„зЁӢеәҸдёӯгҖӮ
load_classes жҳҜеңЁ util.py дёӯе®ҡд№үзҡ„дёҖдёӘеҮҪж•°пјҢе…¶дјҡиҝ”еӣһдёҖдёӘеӯ—е…ёвҖ”вҖ”е°ҶжҜҸдёӘзұ»еҲ«зҡ„зҙўеј•жҳ е°„еҲ°е…¶еҗҚз§°зҡ„еӯ—з¬ҰдёІгҖӮ
еҲқе§ӢеҢ–зҪ‘з»ң并иҪҪе…ҘжқғйҮҚгҖӮ
иҜ»еҸ–иҫ“е…ҘеӣҫеғҸ
д»ҺзЈҒзӣҳиҜ»еҸ–еӣҫеғҸжҲ–д»Һзӣ®еҪ•иҜ»еҸ–еӨҡеј еӣҫеғҸгҖӮеӣҫеғҸзҡ„и·Ҝеҫ„еӯҳеӮЁеңЁдёҖдёӘеҗҚдёә imlist зҡ„еҲ—иЎЁдёӯгҖӮ
read_dir жҳҜдёҖдёӘз”ЁдәҺжөӢйҮҸж—¶й—ҙзҡ„жЈҖжҹҘзӮ№гҖӮпјҲжҲ‘们дјҡйҒҮеҲ°еӨҡдёӘжЈҖжҹҘзӮ№пјү
еҰӮжһңдҝқеӯҳжЈҖжөӢз»“жһңзҡ„зӣ®еҪ•пјҲз”ұ det ж Үзӯҫе®ҡд№үпјүдёҚеӯҳеңЁпјҢе°ұеҲӣе»әдёҖдёӘгҖӮ
жҲ‘们е°ҶдҪҝз”Ё OpenCV жқҘеҠ иҪҪеӣҫеғҸгҖӮ
load_batch еҸҲжҳҜдёҖдёӘжЈҖжҹҘзӮ№гҖӮ
OpenCV дјҡе°ҶеӣҫеғҸиҪҪе…Ҙдёә numpy ж•°з»„пјҢйўңиүІйҖҡйҒ“зҡ„йЎәеәҸдёә BGRгҖӮPyTorch зҡ„еӣҫеғҸиҫ“е…Ҙж јејҸжҳҜпјҲbatch x йҖҡйҒ“ x й«ҳеәҰ x е®ҪеәҰпјүпјҢе…¶йҖҡйҒ“йЎәеәҸдёә RGBгҖӮеӣ жӯӨпјҢжҲ‘们еңЁ util.py дёӯеҶҷдәҶдёҖдёӘеҮҪж•° prep_image жқҘе°Ҷ numpy ж•°з»„иҪ¬жҚўжҲҗ PyTorch зҡ„иҫ“е…Ҙж јејҸгҖӮ
йҷӨдәҶиҪ¬жҚўеҗҺзҡ„еӣҫеғҸпјҢжҲ‘们д№ҹдјҡз»ҙжҠӨдёҖдёӘеҺҹе§ӢеӣҫеғҸзҡ„еҲ—иЎЁпјҢд»ҘеҸҠдёҖдёӘеҢ…еҗ«еҺҹе§ӢеӣҫеғҸзҡ„з»ҙеәҰзҡ„еҲ—иЎЁ im_dim_listгҖӮ
еҲӣе»ә batch
жЈҖжөӢеҫӘзҺҜ
жҲ‘们еңЁ batch дёҠиҝӯд»ЈпјҢз”ҹжҲҗйў„жөӢз»“жһңпјҢе°ҶжҲ‘们еҝ…йЎ»жү§иЎҢжЈҖжөӢзҡ„жүҖжңүеӣҫеғҸзҡ„йў„жөӢеј йҮҸпјҲеҪўзҠ¶дёә Dx8пјҢwrite_results еҮҪж•°зҡ„иҫ“еҮәпјүиҝһжҺҘиө·жқҘгҖӮ
еҜ№дәҺжҜҸдёӘ batchпјҢжҲ‘们йғҪдјҡжөӢйҮҸжЈҖжөӢжүҖз”Ёзҡ„ж—¶й—ҙпјҢеҚіжөӢйҮҸиҺ·еҸ–иҫ“е…ҘеҲ° write_results еҮҪж•°еҫ—еҲ°иҫ“еҮәд№Ӣй—ҙжүҖз”Ёзҡ„ж—¶й—ҙгҖӮеңЁ write_prediction иҝ”еӣһзҡ„иҫ“еҮәдёӯпјҢе…¶дёӯдёҖдёӘеұһжҖ§жҳҜ batch дёӯеӣҫеғҸзҡ„зҙўеј•гҖӮжҲ‘们еҜ№иҝҷдёӘзү№е®ҡеұһжҖ§жү§иЎҢиҪ¬жҚўпјҢдҪҝе…¶зҺ°еңЁиғҪд»ЈиЎЁ imlist дёӯеӣҫеғҸзҡ„зҙўеј•пјҢиҜҘеҲ—иЎЁеҢ…еҗ«дәҶжүҖжңүеӣҫеғҸзҡ„ең°еқҖгҖӮ
еңЁйӮЈд№ӢеҗҺпјҢжҲ‘们 print жҜҸдёӘжЈҖжөӢз»“жһңжүҖз”Ёзҡ„ж—¶й—ҙд»ҘеҸҠжҜҸеј еӣҫеғҸдёӯжЈҖжөӢеҲ°зҡ„зӣ®ж ҮгҖӮ
еҰӮжһң write_results еҮҪж•°еңЁ batch дёҠзҡ„иҫ“еҮәжҳҜдёҖдёӘ int еҖјпјҲ0пјүпјҢд№ҹе°ұжҳҜиҜҙжІЎжңүжЈҖжөӢз»“жһңпјҢйӮЈд№ҲжҲ‘们е°ұ继з»ӯи·іиҝҮеҫӘзҺҜзҡ„е…¶дҪҷйғЁеҲҶгҖӮ
torch.cuda.synchronize иҝҷдёҖиЎҢжҳҜдёәдәҶзЎ®дҝқ CUDA ж ёдёҺ CPU еҗҢжӯҘгҖӮеҗҰеҲҷпјҢдёҖж—Ұ GPU е·ҘдҪңжҺ’йҳҹдәҶ并且 GPU е·ҘдҪңиҝҳиҝңжңӘе®ҢжҲҗпјҢйӮЈд№Ҳ CUDA ж ёе°ұе°ҶжҺ§еҲ¶иҝ”еӣһз»ҷ CPUпјҲејӮжӯҘи°ғз”ЁпјүгҖӮеҰӮжһң end = time.time() еңЁ GPU е·ҘдҪңе®һйҷ…е®ҢжҲҗеүҚе°ұ print дәҶпјҢйӮЈд№ҲиҝҷеҸҜиғҪдјҡеҜјиҮҙж—¶й—ҙй”ҷиҜҜгҖӮ
зҺ°еңЁпјҢжүҖжңүеӣҫеғҸзҡ„жЈҖжөӢз»“жһңйғҪеңЁеј йҮҸиҫ“еҮәдёӯдәҶгҖӮи®©жҲ‘们еңЁеӣҫеғҸдёҠз»ҳеҲ¶иҫ№з•ҢжЎҶгҖӮ
еңЁеӣҫеғҸдёҠз»ҳеҲ¶иҫ№з•ҢжЎҶ
жҲ‘们дҪҝз”ЁдёҖдёӘ try-catch жЁЎеқ—жқҘжЈҖжҹҘжҳҜеҗҰеӯҳеңЁеҚ•дёӘжЈҖжөӢз»“жһңгҖӮеҰӮжһңдёҚеӯҳеңЁпјҢе°ұйҖҖеҮәзЁӢеәҸгҖӮ
еңЁжҲ‘们з»ҳеҲ¶иҫ№з•ҢжЎҶд№ӢеүҚпјҢжҲ‘们зҡ„иҫ“еҮәеј йҮҸдёӯеҢ…еҗ«зҡ„йў„жөӢз»“жһңеҜ№еә”зҡ„жҳҜиҜҘзҪ‘з»ңзҡ„иҫ“е…ҘеӨ§е°ҸпјҢиҖҢдёҚжҳҜеӣҫеғҸзҡ„еҺҹе§ӢеӨ§е°ҸгҖӮеӣ жӯӨпјҢеңЁжҲ‘们з»ҳеҲ¶иҫ№з•ҢжЎҶд№ӢеүҚпјҢи®©жҲ‘们е°ҶжҜҸдёӘиҫ№з•ҢжЎҶзҡ„и§’еұһжҖ§иҪ¬жҚўеҲ°еӣҫеғҸзҡ„еҺҹе§Ӣе°әеҜёдёҠгҖӮ
еҰӮжһңеӣҫеғҸдёӯеӯҳеңЁеӨӘеӨҡиҫ№з•ҢжЎҶпјҢйӮЈд№ҲеҸӘз”ЁдёҖз§ҚйўңиүІжқҘз»ҳеҲ¶еҸҜиғҪдёҚеӨӘйҖӮеҗҲи§ӮзңӢгҖӮе°ҶиҝҷдёӘж–Ү件дёӢиҪҪеҲ°дҪ зҡ„жЈҖжөӢеҷЁж–Ү件еӨ№дёӯпјҡhttps://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch/raw/master/palleteгҖӮиҝҷжҳҜдёҖдёӘ pickle ж–Ү件пјҢе…¶дёӯеҢ…еҗ«еҫҲеӨҡеҸҜд»ҘйҡҸжңәйҖүжӢ©зҡ„йўңиүІгҖӮ
зҺ°еңЁпјҢи®©жҲ‘们еҶҷдёҖдёӘеҮҪж•°жқҘз»ҳеҲ¶иҫ№з•ҢжЎҶгҖӮ
дёҠйқўзҡ„еҮҪж•°жҳҜдҪҝз”Ёд»Һ colors дёӯйҡҸжңәйҖүеҮәзҡ„йўңиүІз»ҳеҲ¶дёҖдёӘзҹ©еҪўжЎҶгҖӮе®ғд№ҹдјҡеңЁиҫ№з•ҢжЎҶзҡ„е·ҰдёҠи§’еҲӣе»әдёҖдёӘеЎ«е……еҗҺзҡ„зҹ©еҪўпјҢ并且еҶҷе…ҘеңЁиҜҘжЎҶдҪҚзҪ®жЈҖжөӢеҲ°зҡ„зӣ®ж Үзҡ„зұ»еҲ«гҖӮcv2.rectangle еҮҪж•°зҡ„ -1 еҸӮж•°з”ЁдәҺеҲӣе»әеЎ«е……зҡ„зҹ©еҪўгҖӮ
жҲ‘们еұҖйғЁе®ҡд№ү write еҮҪж•°дҪҝе…¶иғҪеӨҹиҺ·еҸ–йўңиүІеҲ—иЎЁгҖӮжҲ‘们д№ҹеҸҜд»Ҙе°ҶйўңиүІдҪңдёәдёҖдёӘеҸӮж•°еҢ…еҗ«иҝӣжқҘпјҢдҪҶиҝҷдјҡи®©жҲ‘们еҸӘиғҪеңЁдёҖеј еӣҫеғҸдёҠдҪҝз”ЁдёҖз§ҚйўңиүІпјҢиҝҷжңүиҝқжҲ‘们зҡ„зӣ®зҡ„гҖӮ
жҲ‘们е®ҡд№үдәҶиҝҷдёӘеҮҪж•°д№ӢеҗҺпјҢзҺ°еңЁе°ұжқҘеңЁеӣҫеғҸдёҠз”»иҫ№з•ҢжЎҶеҗ§гҖӮ
дёҠйқўзҡ„д»Јз ҒзүҮж®өжҳҜеҺҹең°дҝ®ж”№ loaded_ims д№Ӣдёӯзҡ„еӣҫеғҸгҖӮ
жҜҸеј еӣҫеғҸйғҪд»ҘгҖҢdet_гҖҚеҠ дёҠеӣҫеғҸеҗҚз§°зҡ„ж–№ејҸдҝқеӯҳгҖӮжҲ‘们еҲӣе»әдәҶдёҖдёӘең°еқҖеҲ—иЎЁпјҢиҝҷжҳҜжҲ‘们дҝқеӯҳжҲ‘们зҡ„жЈҖжөӢз»“жһңеӣҫеғҸзҡ„дҪҚзҪ®гҖӮ
жңҖеҗҺпјҢе°ҶеёҰжңүжЈҖжөӢз»“жһңзҡ„еӣҫеғҸеҶҷе…ҘеҲ° det_names дёӯзҡ„ең°еқҖгҖӮ
жҳҫзӨәиҫ“еҮәж—¶й—ҙжҖ»з»“
еңЁжЈҖжөӢеҷЁе·ҘдҪңз»“жқҹж—¶пјҢжҲ‘们дјҡ print дёҖдёӘжҖ»з»“пјҢе…¶дёӯеҢ…еҗ«дәҶе“ӘйғЁеҲҶд»Јз Ғз”ЁдәҶеӨҡе°‘жү§иЎҢж—¶й—ҙзҡ„дҝЎжҒҜгҖӮеҪ“жҲ‘们еҝ…йЎ»жҜ”иҫғдёҚеҗҢзҡ„и¶…еҸӮж•°еҜ№жЈҖжөӢеҷЁйҖҹеәҰзҡ„еҪұе“Қж–№ејҸж—¶пјҢиҝҷдјҡеҫҲжңүз”ЁгҖӮbatch еӨ§е°ҸгҖҒobjectness зҪ®дҝЎеәҰе’Ң NMS йҳҲеҖјзӯүи¶…еҸӮж•°пјҲеҲҶеҲ«з”Ё bsгҖҒconfidenceгҖҒnms_thresh ж Үзӯҫдј йҖ’пјүеҸҜд»ҘеңЁе‘Ҫд»ӨиЎҢдёҠжү§иЎҢ detection.py и„ҡжң¬ж—¶и®ҫзҪ®гҖӮ
жөӢиҜ•зӣ®ж ҮжЈҖжөӢеҷЁ
жҜ”еҰӮпјҢеңЁз»Ҳз«ҜдёҠиҝҗиЎҢпјҡ
еҫ—еҲ°иҫ“еҮәпјҡ
жіЁпјҡдёӢйқўзҡ„з»“жһңжҳҜеңЁ CPU дёҠиҝҗиЎҢд»Јз Ғеҫ—еҲ°гҖӮеңЁ GPU дёҠзҡ„йў„жңҹжЈҖжөӢж—¶й—ҙдјҡеҝ«еҫ—еӨҡгҖӮеңЁ Tesla K80 дёҠеӨ§зәҰдёәжҜҸеј еӣҫеғҸ 0.1 з§’гҖӮ

еңЁ det зӣ®еҪ•дёӯдҝқеӯҳзҡ„дёҖеј еҗҚдёә det_dog-cycle-car.png зҡ„еӣҫеғҸпјҡ
еңЁи§Ҷйў‘ / зҪ‘з»ңж‘„еғҸеӨҙдёҠиҝҗиЎҢжЈҖжөӢеҷЁ
иҰҒеңЁи§Ҷйў‘жҲ–зҪ‘з»ңж‘„еғҸеӨҙдёҠиҝҗиЎҢиҝҷдёӘжЈҖжөӢеҷЁпјҢд»Јз Ғеҹәжң¬еҸҜд»ҘдҝқжҢҒдёҚеҸҳпјҢеҸӘжҳҜжҲ‘们дёҚдјҡеңЁ batch дёҠиҝӯд»ЈпјҢиҖҢжҳҜеңЁи§Ҷйў‘зҡ„её§дёҠиҝӯд»ЈгҖӮ
еңЁи§Ҷйў‘дёҠиҝҗиЎҢиҜҘжЈҖжөӢеҷЁзҡ„д»Јз ҒеҸҜд»ҘеңЁжҲ‘们зҡ„ GitHub дёӯзҡ„ video.py ж–Ү件дёӯжүҫеҲ°гҖӮиҝҷдёӘд»Јз Ғйқһеёёзұ»дјј detect.py зҡ„д»Јз ҒпјҢеҸӘжңүеҮ еӨ„дёҚеӨӘдёҖж ·гҖӮ
йҰ–е…ҲпјҢжҲ‘们иҰҒз”Ё OpenCV жү“ејҖи§Ҷйў‘ / зӣёжңәжөҒгҖӮ
然еҗҺпјҢжҲ‘们д»ҘеңЁеӣҫеғҸдёҠзұ»дјјзҡ„иҝӯд»Јж–№ејҸеңЁеё§дёҠиҝӯд»ЈгҖӮ
еӣ дёәжҲ‘们дёҚеҝ…еҶҚеӨ„зҗҶ batchпјҢиҖҢжҳҜдёҖж¬ЎеҸӘеӨ„зҗҶдёҖеј еӣҫеғҸпјҢжүҖд»ҘеҫҲеӨҡең°ж–№зҡ„д»Јз ҒйғҪиҝӣиЎҢдәҶз®ҖеҢ–гҖӮеӣ дёәдёҖж¬ЎеҸӘеӨ„зҗҶдёҖеё§гҖӮиҝҷеҢ…жӢ¬дҪҝз”ЁдёҖдёӘе…ғз»„жӣҝд»Ј im_dim_list зҡ„еј йҮҸпјҢ然еҗҺеҜ№ write еҮҪж•°иҝӣиЎҢдёҖзӮ№е°Ҹдҝ®ж”№гҖӮ
жҜҸж¬Ўиҝӯд»ЈпјҢжҲ‘们йғҪдјҡи·ҹиёӘеҗҚдёә frames зҡ„еҸҳйҮҸдёӯеё§зҡ„ж•°йҮҸгҖӮ然еҗҺжҲ‘们用иҝҷдёӘж•°еӯ—йҷӨд»ҘиҮӘ第дёҖеё§д»ҘжқҘиҝҮеҺ»зҡ„ж—¶й—ҙпјҢеҫ—еҲ°и§Ҷйў‘зҡ„её§зҺҮгҖӮ
жҲ‘们дёҚеҶҚдҪҝз”Ё cv2.imwrite е°ҶжЈҖжөӢз»“жһңеӣҫеғҸеҶҷе…ҘзЈҒзӣҳпјҢиҖҢжҳҜдҪҝз”Ё cv2.imshow еұ•зӨәз”»жңүиҫ№з•ҢжЎҶзҡ„её§гҖӮеҰӮжһңз”ЁжҲ·жҢү Q жҢүй’®пјҢе°ұдјҡи®©д»Јз Ғдёӯж–ӯеҫӘзҺҜпјҢ并且и§Ҷйў‘з»ҲжӯўгҖӮ
жҖ»з»“
еңЁиҝҷдёӘзі»еҲ—ж•ҷзЁӢдёӯпјҢжҲ‘们д»ҺеӨҙејҖе§Ӣе®һзҺ°дәҶдёҖдёӘзӣ®ж ҮжЈҖжөӢеҷЁгҖӮжҲ‘иҝҳи®Өдёәзј–еҶҷй«ҳж•Ҳзҡ„д»Јз ҒжҳҜж·ұеәҰеӯҰд№ е®һи·өиҖ…еә”иҜҘе…·еӨҮзҡ„дҪҶеҚҙжңҖиў«дҪҺдј°зҡ„жҠҖиғҪгҖӮдёҚз®ЎдҪ зҡ„жғіжі•еҸҜиғҪе…·жңүеӨҡеӨ§зҡ„йқ©е‘ҪжҖ§пјҢеҰӮжһңдҪ дёҚиғҪжөӢиҜ•е®ғпјҢе®ғе°ұжҜ«ж— з”ЁеӨ„гҖӮдёәжӯӨпјҢдҪ е°ұйңҖиҰҒеҫҲејәзҡ„еҶҷд»Јз ҒиғҪеҠӣгҖӮ
жҲ‘д№ҹи®ӨиҜҶеҲ°пјҢеӯҰд№ ж·ұеәҰеӯҰд№ зҡ„жңҖдҪіж–№жі•жҳҜе®һзҺ°ж·ұеәҰеӯҰд№ д»Јз ҒгҖӮиҝҷиғҪиҝ«дҪҝдҪ е…іжіЁдёҖдёӘдё»йўҳзҡ„з»Ҷеҫ®дҪҶеҸҲеҹәзЎҖзҡ„йғЁеҲҶвҖ”вҖ”еҰӮжһңеҸӘиҜ»и®әж–ҮпјҢдҪ еҸҜиғҪдјҡй”ҷиҝҮиҝҷдәӣең°ж–№гҖӮжҲ‘еёҢжңӣиҝҷдёӘзі»еҲ—ж•ҷзЁӢиғҪеё®еҠ©дҪ зЈЁз әдҪ зҡ„ж·ұеәҰеӯҰд№ е®һи·өжҠҖиғҪгҖӮ
жү©еұ•йҳ…иҜ»
PyTorch ж•ҷзЁӢпјҡhttp://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
еҗҙжҒ©иҫҫи§ЈйҮҠ IoUпјҡhttps://youtu.be/DNEm4fJ-rto
еҗҙжҒ©иҫҫи§ЈйҮҠйқһжһҒеӨ§еҖјжҠ‘еҲ¶пјҡhttps://youtu.be/A46HZGR5fMw
OpenCV еҹәзЎҖпјҡhttps://pythonprogramming.net/loading-images-python-opencv-tutorial/
еҺҹж–Үй“ҫжҺҘпјҡhttps://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch-part-5/
