无数公司利用机器学习解决特定问题,在各行各业落地:有落地人脸识别的,有落地语音识别和翻译的,有落地广告推荐的,有落地金融和保险的,有落地自动驾驶的,还有落地产线提高生产效率的。虽然AI的奠基者们Marvin Minsky等人在2004年呼吁大家应该不要过多关注AI解决例如下棋、开车、翻译等特定问题,而应该更多的关注AI像人类一样思考和行动,但还是不妨碍各行业在解决特定问题上的努力。
深度学习框架是继Hadoop和Spark之后最重要、最核心的基础设施软件,而一流科技就是一家专注于研发新一代深度学习框架的公司,创始人袁进辉向36氪记者表述,一开始创业时就决定要做开源,但后来者做开源要成功必须有一鸣惊人的实力。常识认为,以创业公司身份研发通用深度学习框架难以和大厂竞争,但这个赛道的竞争归根结底是产品品质的竞争,此类产品从竞争中胜出归根结底靠创新能力,而创新能力上初创企业不见得比巨头弱。一流的目标就是打造世界上先进、受用户欢迎的深度学习框架,降低企业使用人工智能技术的成本和难度,而且AI之后会作为基础设施软件,每家企业都有自己的应用和演进,如果不开源很难得到大范围使用。
OneBrain平台操作界面
一流科技经过四年的发展,研发团队从3人扩展到40人,完成了世界上少有的可支持超大规模深度学习模型训练的深度学习框架 -OneFlow,和供用户使用的AI开放平台 -OneBrain。袁进辉表示OneFlow和OneBrain是通用型,可以解决各行业碰到的绝大部分的问题,而不仅仅解决特定问题而存在的。一流科技深度学习产品完全自主知识产权,已获得十余项发明专利授权,拥有自动数据模型混合并行、静态调度、去中心化和全链路异步流式执行四大核心技术,解决了在异构分布式集群上训练大规模深度学习模型所面临的大数据、大模型、大计算挑战。在2020年5月由中国信通院发布的《首轮开源深度学习软件框架测试报告》中,OneFlow框架在同样的算法和硬件条件下性能指标大幅领先国外产品。
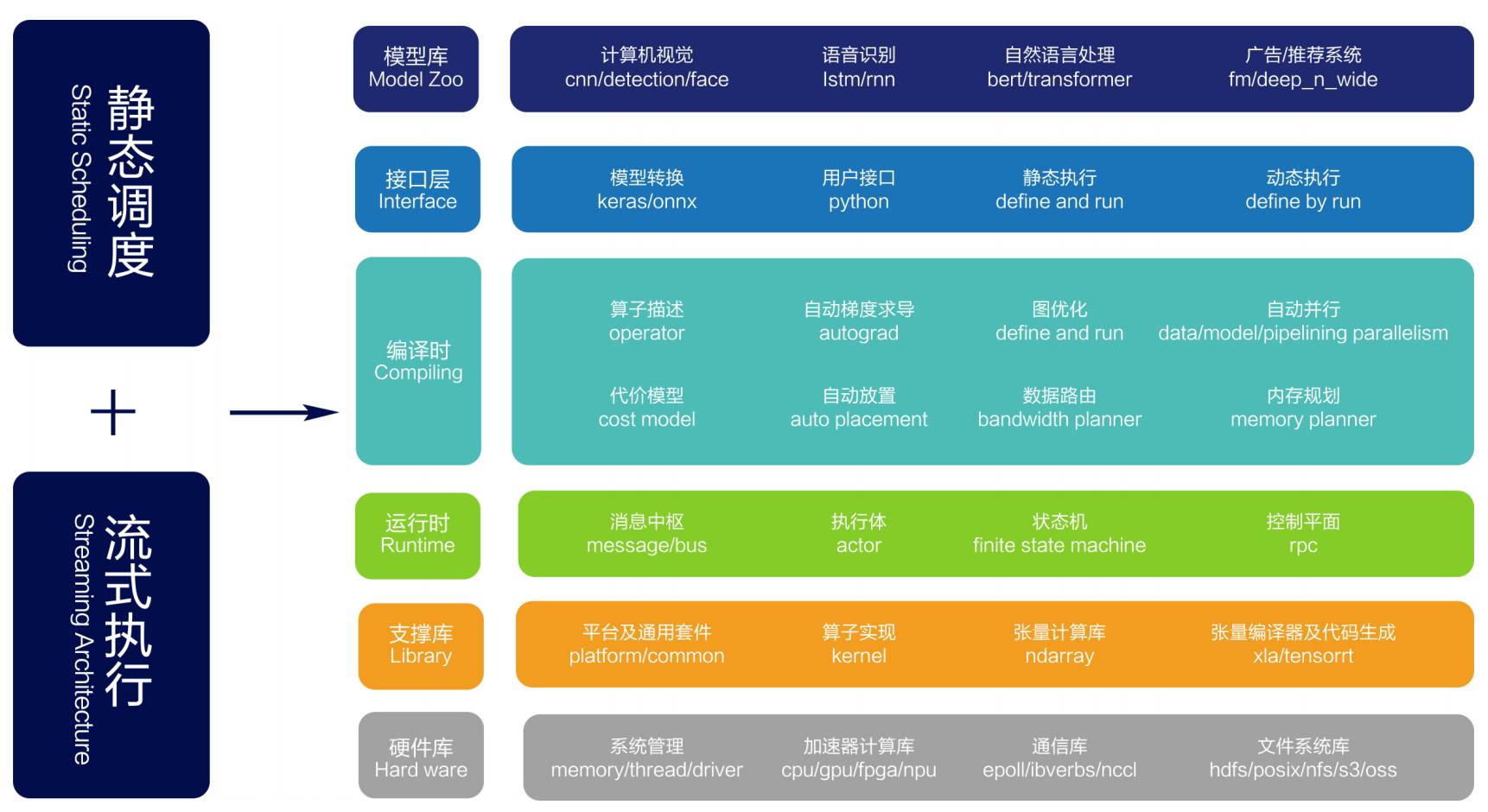
OneFlow框架
超大规模神经网络模型的训练和应用,是自2019年前后由谷歌和OpenAI带动起来的新方向。之前的神经网络虽然数据多但模型小,层数和连边很小,只有千万级或亿级参数,2019年谷歌开始搞大的模型,十亿级、千亿级的模型参数。大模型的好处简单讲:先做大模型,再训练,同样数据量得到的效果比小模型更好,很多场景小模型训练无法得到大模型的准确度,训练结束后可再将大模型冗余参数去掉缩小模型,最后部署使用。大模型在很多应用场景都超过了常见的卷积神经网络方法,例如NLP这种非视觉的应用、人脸识别这种参数量很大的应用、广告推荐行业等。目前,一流科技的客户有之江实验室、北京智源人工智能研究院、中关村智用研究院、中国科学院自动化研究所、搜狗、深醒等企事业单位。据悉,一流科技将在2021年开展探索类似Snowflake和Databricks已验证的公有云服务的商业模式。
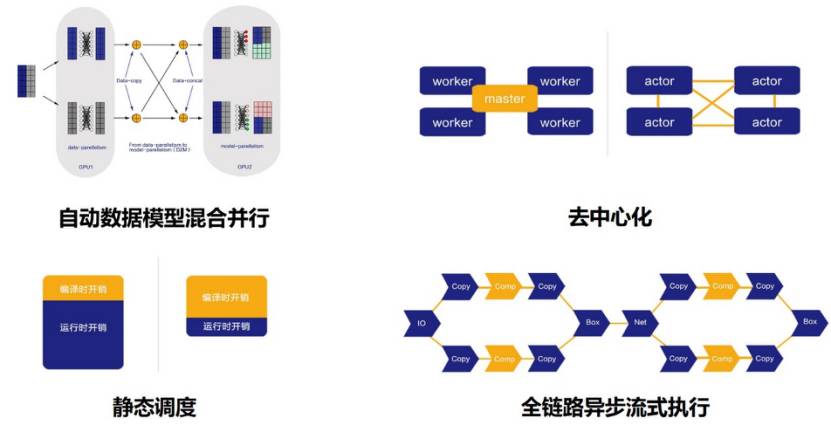
一流科技四大核心技术
袁进辉向36氪记者表述,用户对开源深度学习框架的主要需求如下:
运行效率:在同样的算法和硬件条件下,效率一定要快,这样能最大程度降低用户的成本,这样才会有实用前景,这个维度在技术上是最挑战,也是OneFlow的最有优势的地方;易用性:易用性是很多AI学术和公司忽略的一点,目前易用性做得最好的是PyTorch,这也是它能大范围实用的原因之一,一流科技的目标是让OneFlow新版本像PyTorch一样容易使用;框架工具是否完备:OneBrain开放平台还要帮用户做数据标注、清洗、模型库、可视化、训练部署、集群管理等,这样用户不操心底层问题,不至于需要打仗还得去造坦克。
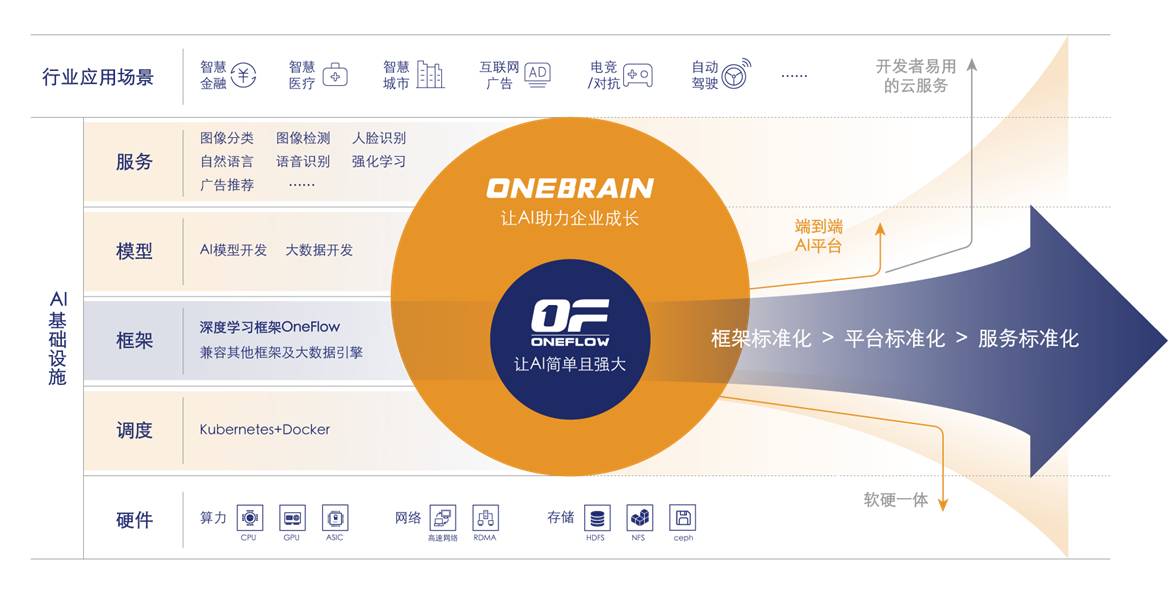
目标:让AI成为标准化产品
人工智能Artificial Intelligence近几年在全球范围都发展迅猛,从感知到学习,但到底具有什么样的特性才能算作AI,在Stuart J. Russell 《Artificial Intelligence A Modern Approach》的权威解释是分为四个方向:像人类一样思考,像人类一样行动,纯理性的思考,纯理性的行动。这四个方向,不同的学者和企业家都在用不同的方式去探索,涉及的学科越来越多,已经不只是单纯的数学和计算机工程:
例如图灵测试就是判断机器是否像人类一样行动,单单是这个方向就涉及了自然语言处理NLP-让机器能用英文交流、信息存储-让机器存储感知到的、逻辑分析-让机器用存储的信息逻辑分析回答问题、机器学习Machine Learning-让机器适应未知环境并在其中发现新的模式、机器视觉-让机器感知外部环境;机器是否像人类一样思考,能否帮助人类解决问题,Newell和Simon在1961年提出了认知科学领域的General Problem Solver,GPS目的不是逻辑推理,而是模拟人类解决问题,机器是否纯理性的思考,逻辑学在19世纪就以及开始用严谨的语句和语法来进行推理,尝试得到最理性的答案,1965年已经能将其计算机程序化;纯理性的行动更为复杂,包含了前面的纯理性的思考和行动两部分,它就是我们常说的Rational Agent,在给定环境中采取可能最优解的行动,也是众多企业落地的方向。
根据公开信息,36氪记者稍稍对机器学习在各行业做了如下几个阶段的企业分类,如有遗漏或错误请联系36氪记者:
AI从1982年开始了商用专家系统,是建立在规则的基础上做算法;然后是80年代大家将注意力重新回到神经网络Neural Networks,但由于当时缺乏大数据和GPU硬件算力,神经网络并没有发展起来;直到90年代,统计机器学习Statistics ML兴起,才开始大面积商用来解决现实世界的问题,不再局限于模型世界,统计机器学习简单讲就是用统计优化算法推导规律,也就是用数据调整算法,并且能对未来预测,例如决策树、贝叶斯网络Bayesian Network、支持向量机、Adaboost都属于统计机器学习。这些偏传统的机器学习方法在特定领域仍有广泛应用,譬如保险金融行业,这些方面的知名企业有第四范式、九章云极等。2012年深度学习Deep Learning兴起,神经网络的优势是不用人去设计特征,替代了传统机器学习,当时流行的深度学习框架有Caffe和Theano声明式编程风格、Chainer命令式编程风格。其中最受欢迎且一直使用至今的模型就是卷积神经网络CNN,因为卷积神经网络是受大脑视觉通路的生物神经网络的结构启发,特别适合做计算机视觉和图片分类(人脸识别除外),但不适合做NLP和广告推荐系统。凭借卷积神经网络在计算机视觉里的成功应用而快速发展起来的企业有旷视、商汤、依图、云从等。2012年之后大家都不停去试新的神经网络结构,发论文,找应用落地,让小模型的神经网络结构得到创新发展,例如循环神经网络RNN用于学习具有前后相关的数据类型,适合进行语言翻译或文本翻译。因为所有的深度学习都属于统计机器学习,特点是数据越大用相同的算法准确率越高,也就是说可以用数据量堆出准确度,这就让大数据释放了巨大的潜能,例如现在用30亿张图片训练卷积神经网络、BERT等。目前国内外开源的适合解决大数据、小模型的深度学习框架有谷歌开源TensorFlow、Facebook开源PyTorch、微软研究院CNTK框架、Amazon MXNet,国内的企业有旷视开源MegEngine、百度开源飞浆等。2019年之后,大模型的神经网络表现出了小模型无法比拟的优势,如何支持超大规模深度学习模型的训练成为深度学习框架的重要研发方向。谷歌基于TensorFlow开发了Mesh-Tensorflow和Gpipe等技术,微软DeepSpeed改造了PyTorch,但只支持NLP,Nvidia Megatron-LM只做NLP,Nvidia HugeCTR只做广告推荐,这些方案的通用性不够好,影响了它们的推广应用。谷歌最近在XLA上开发了GShard技术,试图解决通用性问题,但尚未开源。在这个方向上探索较深的国产深度学习框架包括华为开源的MindSpore,一流科技开源的OneFlow,和Google GShard论文描述的思路异曲同工,通用性最好。2020年开始,小样本训练的问题也越来越引起行业的重视,重点解决数据量不够的场景,例如工业数据,用小样本训练就能完成同样准确度,颠覆深度学习,例如强化学习RL中的生成对抗网络GAN,图像数据可以通过旋转、裁切或改变明暗等方式增加数据量,目前有相当多领域透过GAN方法生成非常近似原始数据的数据,但因为比较新颖,还没有成熟的方案解决通用问题。国内在小样本训练方向探索较深的公司有暗物智能、瑞莱智慧等。
